Dataflows

Un Dataflow est un ensemble de transformations de données représentable sous forme de graphique.
Par exemple, vous pouvez charger votre base produits à partir d'un fichier CSV sur un SFTP, puis charger votre base de clients et votre base de ventes à partir de tables SQL; puis calculer pour chaque client ses meta-infos (son CA total, son nombre d'achat, sa date de dernier achat...). Ensuite, vous pouvez fusionner les ventes avec ces meta-infos pour créer un dashboard dans lequel vous pouvez filtrer vos ventes pour les clients qui ont fait plus de 100€ de CA.
Pour de nombreux projets, cette préparation de données est nécessaire. Vous pouvez la réaliser avec une stack d'outils dédiés (AWS Redshift, Kestra.io, dbt, Airbyte...) mais cela demande des compétences techniques fortes.
Avec Serenytics, tout est intégré et simple à utiliser, et suffisant pour de très nombreux projets.
Les Dataflows reposent sur 3 composants intégrés dans Serenytics:
- Les étapes de transformations de données (ETL step, Pivot, chargement SFTP, script Python...). Voir ci-dessous.
- Le datawarehouse interne pour stocker ces données. En savoir plus...
- Le scheduler pour déclencher automatiquement tous les traitements. En savoir plus...
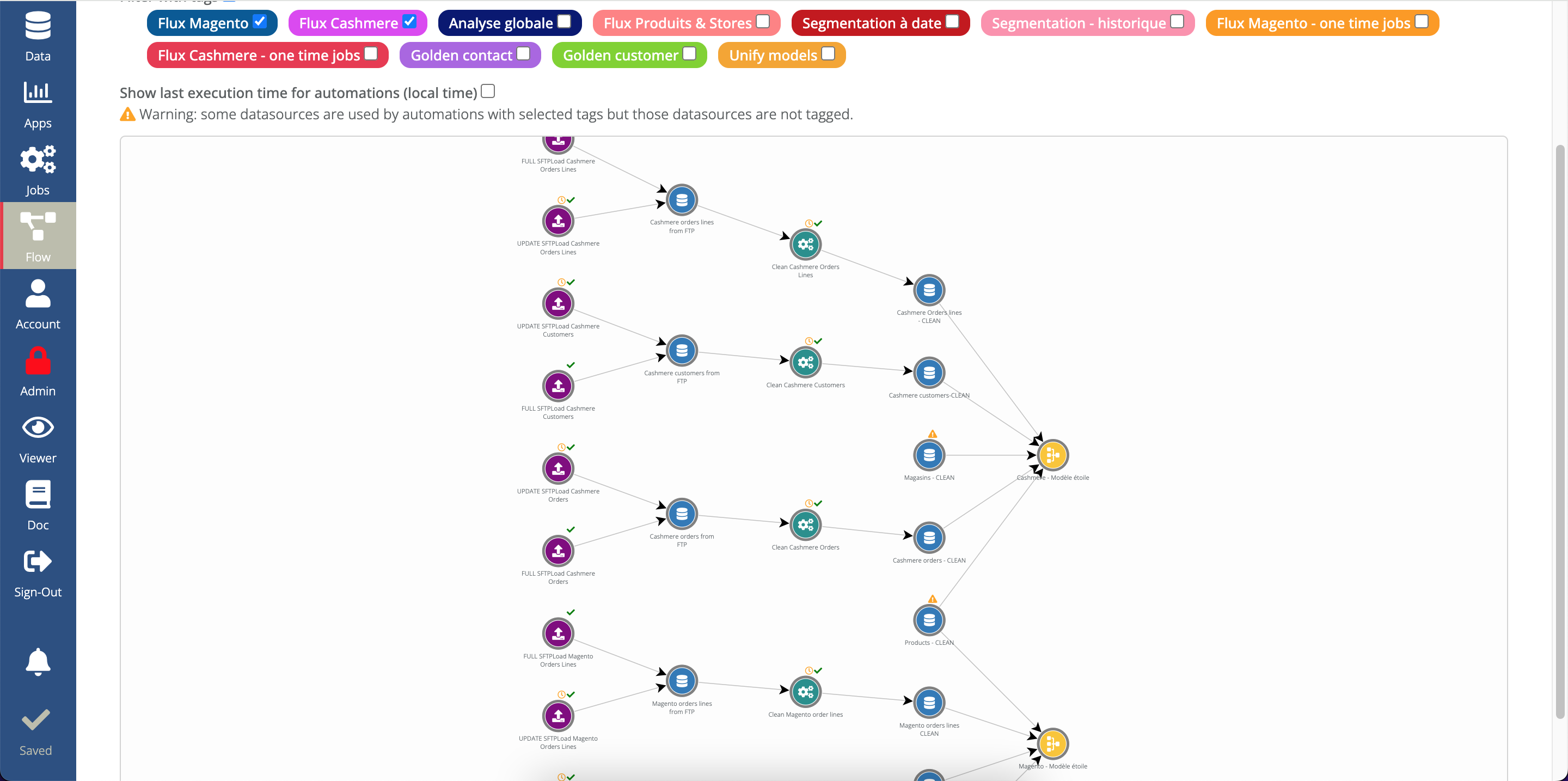
Vous pouvez configurer de manière graphique une étape d'ETL (extract/transform/load), sans écrire de SQL.
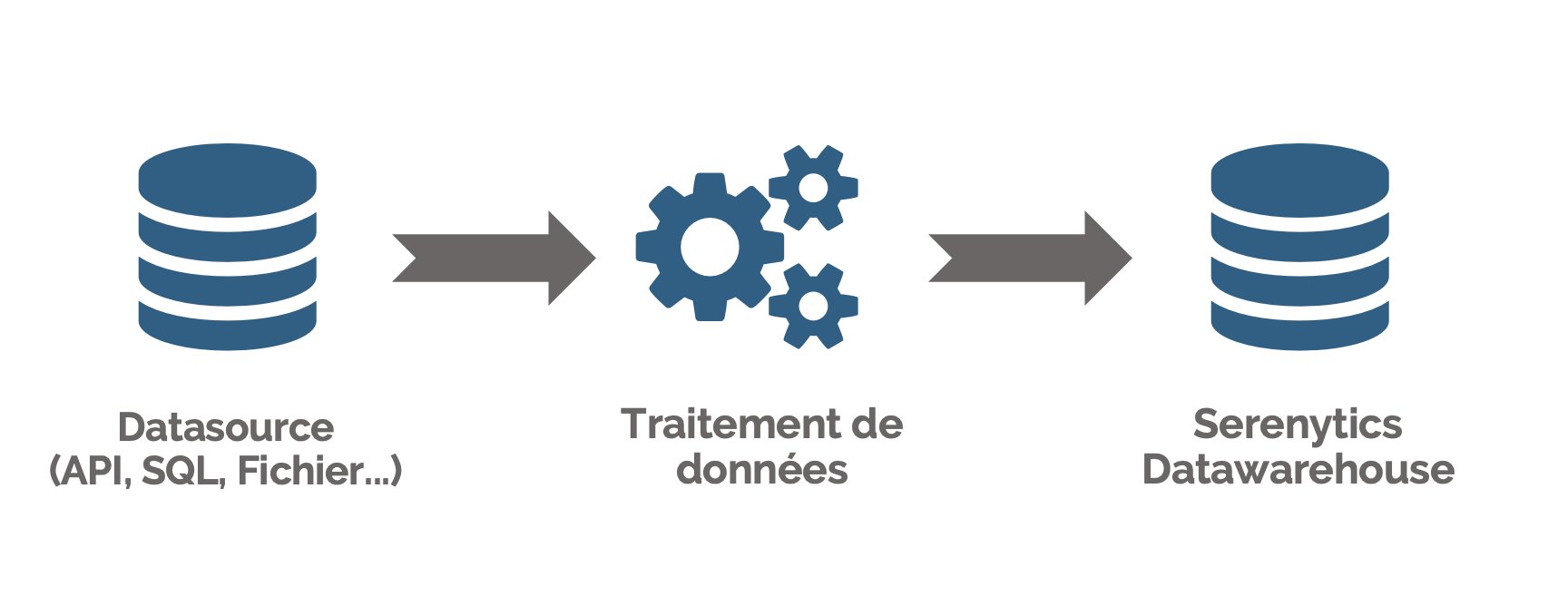
Un ETL step vous permet de :
- charger des données depuis une source de données quelconque,
- définir la transformation de données à appliquer à ces données (sélection de colonnes, aggrégation, filtrage, calculs de nouvelles colonnes, renommages...)
- stocker le résultat de la transformation dans une table de données de notre datawarehouse interne.
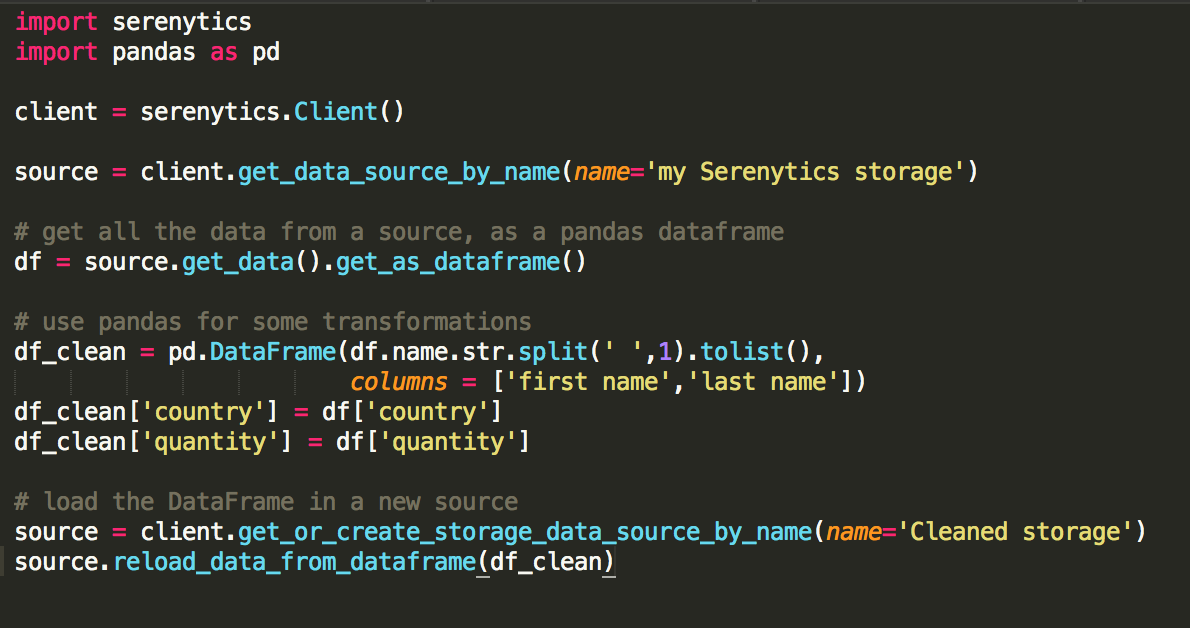
Si les ETL steps ne sont pas suffisants, Serenytics inclut un module d'exécution de scripts Python.
Vous pouvez coder tous vos traitements de données (import, export, calculs avancés, nettoyage de données, machine learning, analyses prédictives ...) et les exécuter de manière régulière via notre scheduler ou en déclenchant leur exécution via un appel d'API REST. Cela vous d'avoir à gérer votre propre infrastructure de tâches de traitement de données.
Dans un script Python, vous pouvez utiliser le package Serenytics. Celui-ci fournit de nombreuses fonctions qui vous permettent d'interroger une source de données configurée dans l'interface (avec des agrégats et des filtrages). Le résultat de cette requête peut être manipulé avec le langage Python, souvent en utilisant des librairies comme Pandas ou bien Scikit-learn. Enfin, la librairie Serenytics vous permet de charger votre résultat dans notre Datawarehouse interne pour visualiser les résultats.
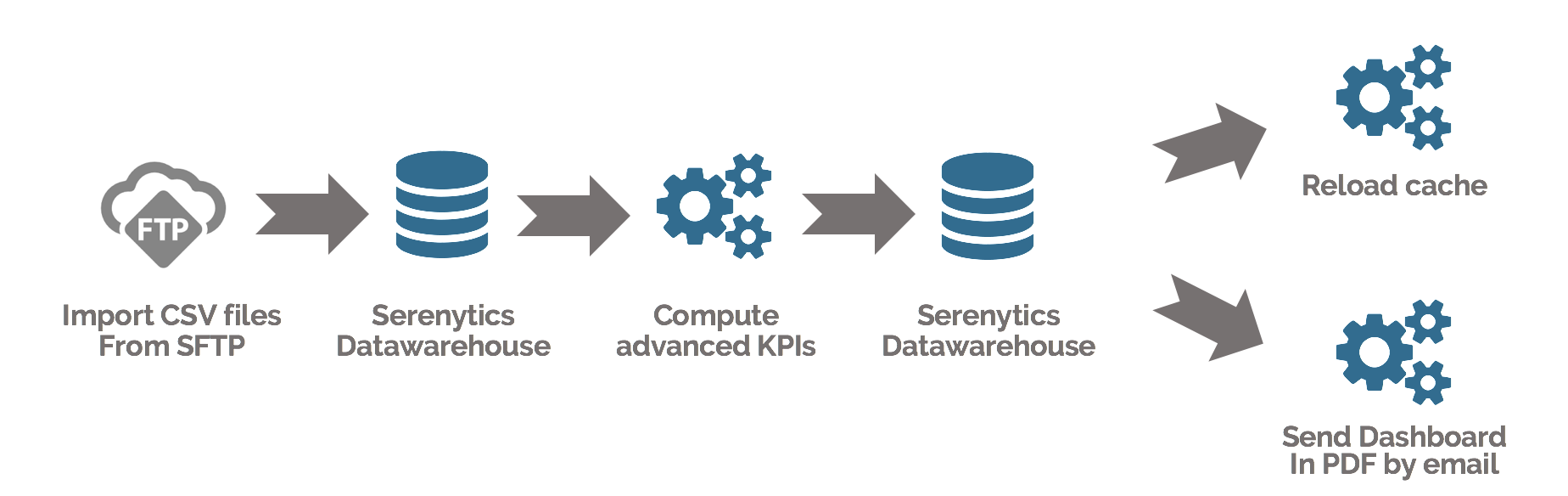
Notre moteur vous permet de créer un flow qui va enchainer plusieurs étapes (ETL ou script Python). Avec notre scheduler, vous pouvez programmer l'exécution de ce flow quand vous le souhaitez.
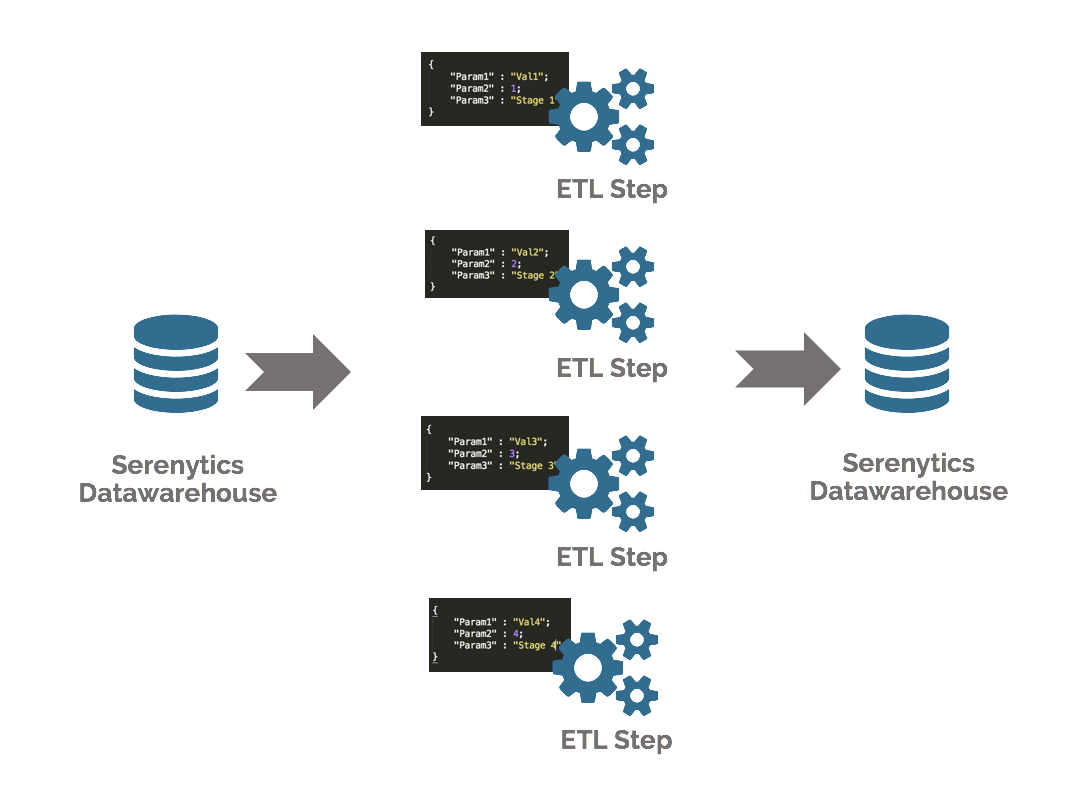
Certaines formules sont parfois dépendantes d'un paramètre. Par exemple la fonction "a fait un achat dans les 12 derniers mois" dépend du mois auquel on évalue cette fonction.
Pour gérer ce point, Serenytics vous permet d'ajouter des paramètres dans vos fonctions sur vos sources de données (par exemple un paramètre "mois de calcul") et de lancer le calcul de vos étapes d'ETL plusieurs fois (une fois pour chaque valeur de paramètre).Les résultats de chaque exécution sont concaténés dans une table dans notre datawarehouse interne. En quelques clics, vous mettez en place des traitements de données très avancés. Cela vous permet par exemple de construire l'historique du nombre de clients actifs dans une base clients.