Internal datawarehouse

In a simple project, all you have to do is connect your data and create your dashboards.
But very often, you also need to add Dataflows to prepare your data, for example to cleanse it or to calculate statistics on customer data before displaying it, to merge sales data with objectives defined in an XLS file... There are many reasons for this.
The internal datawahouse allows you to store all this intermediate data without having to configure anything and without needing a Data Engineer in your team. It is automatically set up when your account is created.
It is based on PostGreSQL or AWS Redshift technology for large volumes of data (up to 500 million rows).
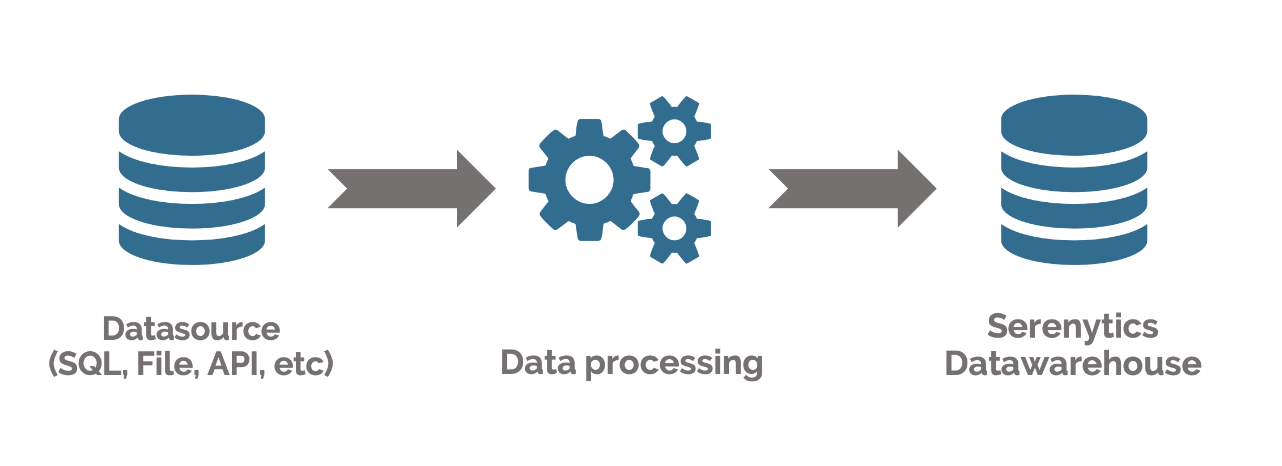
Serenytics has an internal data warehouse to make the life of your data project easier. There are several ways to load this datawarehouse (flat files on SFTP, sending of files by API, synchronization with another data source ...). The advantage for you is that you do not have to implement this datawarehouse (and its monitoring, its backups, its version upgrades ...). Then this datawarehouse can be used as a data source for your dashboards.
Serenytics' internal data warehouse can be used on large volumes of data. With its column-oriented / clustered technology, you can load hundreds of millions of lines while maintaining excellent performance.
Our datawarehouse is also useful for storing the results of your data processing. If you use our ETL or write your own Python data processing scripts, our internal datawarehouse is a very simple solution to store the results and then view them in your dashboards.
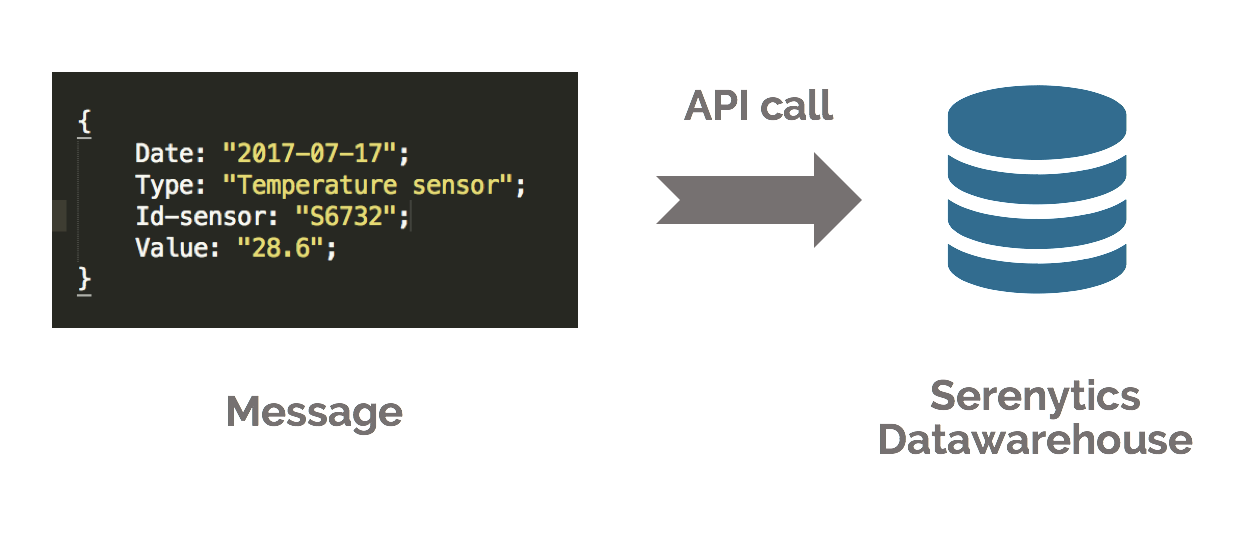
You can add a data line to our datawarehouse by a simple API call. This allows you to store events or messages very easily. Our API is asynchronously architected to handle large volumes of messages. For example, this system can be very useful for storing and then viewing data for IoT projects, or to track clicks & actions done by your users in an app.